In this post I cover my solution to Brent Ozar’s recent query exercise, where we needed to optimize a query so that it’s able to find long values fast.
Introduction
Brent provides the following index and query.
| 1 2 3 4 5 6 7 | USE StackOverflow GO CREATE INDEX DisplayName ON dbo.Users(DisplayName); GO SELECT * FROM dbo.Users WHERE LEN(DisplayName) > 35; |
Requirements
- Why is SQL Server’s estimated number of rows here so far off? Where’s that estimate coming from?
- Can you get that estimate to be more accurate?
- Can you get the logical reads to drop 100x from where it’s at right now?
Now, because in the real world we can’t always get developers/ISVs to change their queries, I’d like to keep the query untouched. So that will be my bonus requirement.
My setup
I’m running SQL Server 2019 Dev Edition with CU23, the version of the StackOverflow database that I’m using is the 180GB one. The Users table consists of 8917507 records and the only index that it has at the moment is the clustered index on Id.
Baseline
I create the index supplied by Brent and do a test run of the query.
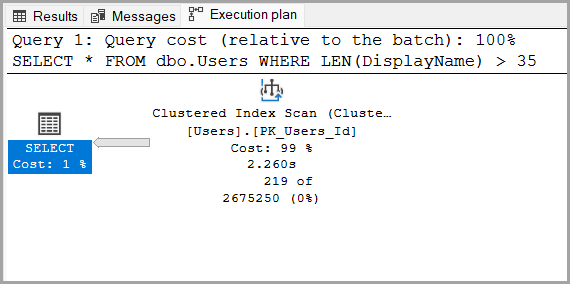
The execution plan is, as expected, pretty bad.
The plan’s cost is 115. Not great, not terrible.
Let’s see how the IO stats look.
(219 rows affected)
Table ‘Users’. Scan count 1, logical reads 141573, physical reads 2, page server reads 0, read-ahead reads 141574,
page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0,
lob read-ahead reads 0, lob page server read-ahead reads 0.
The plan coupled with the 141573 logical reads match Brent’s scenario perfectly.
Solution
First, I’ll address the first point from the list of requirements.
Why is SQL Server’s estimated number of rows here so far off? Where’s that estimate coming from?
As outlined in the execution plan, SQL Server’s Cardinality Estimation says that 2675250 records will need to be fetched in order to satisfy the query.
But the actual number of records returned is 219, so that’s a bit of an overkill.
How many records does the Users table actually have?
| 1 | SELECT COUNT(*) FROM dbo.Users; |
The above query returns 8917507.
That’s interesting. Time to do some math.
| 1 | SELECT 2675250 * 100/ 8917507. AS [%OfAllRecords]; |
This returns 29.99997645, so pretty much 30% of the table.
That’s a pretty specific estimate, a little too specific actually.

Every time I see a suspicious estimate, I’m 99% certain that SQL Server is using a hard-coded estimate percentage, just like in this case.
This is acceptable if you’re dealing with small tables, but once your tables start getting in “tens of millions of records and above” territory things will start getting noticeably slow.
Improve estimates and logical reads
Here I’ll split our options in two.
A key lookup is not as bad as reading 141573 8KB pages
For this option, I add a computed column and then slap a nonclustered index on it.
| 1 2 3 4 5 6 7 | USE StackOverflow GO ALTER TABLE dbo.Users ADD DisplayNameLength AS LEN(DisplayName); GO CREATE INDEX DisplayNameL ON dbo.Users(DisplayNameLength) WITH(ONLINE=OFF, MAXDOP=0); GO |
Clear the buffer and plan cache.
| 1 2 | DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; |
Now, I run the query again and see how it performs.

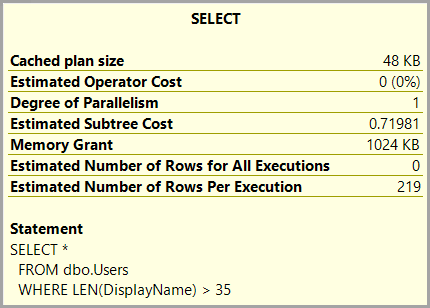
Ok, the cost went down to 0.719. The execution time is sub-second.
The Index Scan is now an Index Seek on the index created for the computed column, our estimates are spot on and the operators don’t take anywhere near the original time to process their work. For reference the index scan from the original plan took 2.26 seconds on my environment.
But we do get that Key Lookup that accounts for 99% of the relative cost.
And because we get that Key Lookup, we also get * queue dramatic music *
(219 rows affected)Table ‘Users’. Scan count 1, logical reads 1317, physical reads 2, page server reads 0, read-ahead reads 1936, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Yup, we get 1317 logical reads because the index only satisfies the WHERE clause, but, because we’re doing SELECT *, the database engine needs to go back to the Clustered Index and do a Key Lookup to get the rest of columns for the records returned by the Index Seek.
Does this fulfill the two requirements about estimates and page reads? It does.
And this is actually a good enough solution, especially if some other query might filter for shorter strings as opposed to strings longer than 35 characters.
But, for this specific exercise, what if I told you that…

Avoiding the key lookup altogether
This option implies that both the WHERE clause and the list of columns can be satisfied in one single operation.
So, it would require an object that contains the pre-filtered records.
It would be pretty neat if SQL Server would allow for a filtered index to be created on a computed column, so that we could have an index on the previously added DisplayNameLength column, with a filter that matches the WHERE clause, and then have the other columns as included columns.
Something like this:
| 1 2 3 4 5 6 7 | USE StackOverflow GO CREATE INDEX DisplayNameLFiltered ON dbo.Users([DisplayNameLength]) INCLUDE ([AboutMe], [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId]) WHERE DisplayNameLength > 35; |
In this way, the index would only contain the records that match the query’s WHERE clause and will also satisfy the SELECT * part, without taking up as much space as the table itself.
Unfortunately, this isn’t an option, so we’ll have to use the next best thing – an indexed view.
First, I cleanup the index and the computed column.
| 1 2 3 4 5 6 | USE StackOverflow GO DROP INDEX DisplayNameL ON dbo.Users; GO ALTER TABLE dbo.Users DROP COLUMN DisplayNameLength; GO |
I then create the following view.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | USE StackOverflow GO CREATE VIEW v_LongUsers WITH SCHEMABINDING AS SELECT [Id], [AboutMe], [Age], [CreationDate], [DisplayName], [DownVotes], [EmailHash], [LastAccessDate], [Location], [Reputation], [UpVotes], [Views], [WebsiteUrl], [AccountId], [CheckSum] FROM [dbo].[Users] WHERE LEN([DisplayName]) > 35; GO |
And I create a clustered index on it.
| 1 2 3 4 5 6 | USE StackOverflow GO CREATE UNIQUE CLUSTERED INDEX CIX_VLongUsers ON v_LongUsers([Id]) WITH(ONLINE=OFF, MAXDOP=0); GO |
Free the buffer and plan cache once more.
| 1 2 | DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; |
And rerun the query to see what happens.
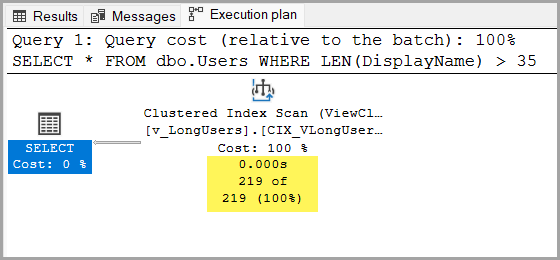
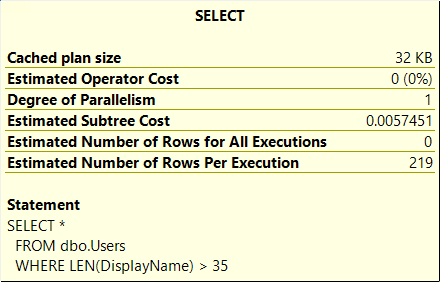
The plan has a Clustered Index Scan on the indexed view, but that’s ok seeing as it only contains the 219 records that the query needs.
The execution time is sub millisecond in this case and the plan cost is 0.005.
Now, in terms of 8KB pages:
(219 rows affected)
Table ‘v_LongUsers’. Scan count 1, logical reads 6, physical reads 1, page server reads 0, read-ahead reads 4,
page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0,
lob read-ahead reads 0, lob page server read-ahead reads 0.
SQL Server only has to read 6 of them to satisfy this query.
Now there is a gotcha here – the database engine will use the indexed view instead of the table, without changes to the query, only if you’re on Enterprise Edition (or Developer Edition in this case).
For Standard Edition, you’ll either have to re-write the query to use the NOEXPAND hint, which breaks the bonus requirement, or use the computed column plus NC index combination, which would be the only viable solution.
Conclusion
Indexed views can save the day in the case of some non-SARGable queries that cannot be re-written.